Köpa eller inte köpa, är vi bara vänner och borde jag skaffa husdjur är dagliga problem som människor grubblar över natt och dag. Nu behöver man inte göra det mera! Garth Sundem hara nu kommit på många enkla sätt att lösa dagliga frågor och problem som människan ställer till sig själv. Garth har skrivit en bok, ”Insinöörin logiikka”, som innehåller en stor mängd formler, med vilka man kan lösa människans dagliga frågor och problem.
Nedan finns det fyra formler från hans bok som du kan ha nytta kanske redan idag.
Köpa eller inte köpa?
Om man hittar något föremål på stan som man genast faller för, får många behovet att direkt köpa det. Nu finns det en formel som kommer att berätta för dig om det är ett vettigt alternativ att köpa föremålet eller inte.

K = Hur mycket behöver jag föremålet? (1-10, om 10 är ”detta är viktigare än min flickvän/pojkvän.”)
H = Hur mycket vill jag ha föremålet? (1-10, om 10 är ”sålde fruns retur-biljett på Huuto.net för att få saken.”)
S = Hur bra investering är det? (1-10, om 10 är ”livets bästa investering.”)
M = Hur många månader har du vilja ha föremålet?
P = Din månadslön.
L = Summan av räkningarna som du får ungefär per månad (om summan är allt för skrämmande, sätt antal räkningar istället.)
V = Hyran.
T = Saldot på ditt konto för tillfälle.
O = Priset på föremålet.
Om Osta ≥ 1 KÖP!
Bara vänner?
Att veta om man är bara vänner eller inte, är något även de lärde tvista om.
Tack och lov finns det en formel även för detta, som hjälper dig att veta var ert förhållande ligger och om det finns en möjlighet att gå vidare.

P = Till vilken ”base” har du varit till, med henne/honom (0-4, om 4 är ”strike.”)
Kp = Hur många gånger har du sluppit till någon ”base”.
Kg = Hur många gånger har ni haft den senaste månaden ”roligt”?
V = Hur attraktiv är hon/han? (1-10, om 1 är ”det är skönheten på insidan som räknas.”)
S = Hur många gånger har du försökt ha ett förhållande med henne/honom?
T = Hur många månader har du känt henne/honom? (Talet kan vara max 36, även om du har känt henne/honom längre.)
Y = Hur likadan är er backgrund och målsättning? (1-10, om 10 är ”som ler och långhalm.”)
A = Hur mycket uppskattar du er vänskap? (1-10, om 10 är ”lova donera min organ till henne/honom.”)
Suhde ≥ 0, grattis, du ligger inte i ”the friendzone”.
Borde jag visa min lägenhet?
Nu när du har börjat träffa någon trevlig och ni har varit på ett par träffar, så har du tänkt att möjligen ta henne/honom till din lägenhet. Du är dock inte säker på om du borde göra det, ifall din lägenhet inte är tillräckligt bra för att göra ett gott intryck. 
Vs = Hyran / återbetalning av lån
A = Bor du ännu hos föräldrarna? (0 = nej, 2 = jo.)
H = Din ålder.
Vh= Hennes/hans hyra/återbetalning av lån
S = Hur många veckor har ni sällskapat?
M = Hur många gånger har du varit hemma hos henne/honom?
W = Hur många dagar sedan du tvättat wc-byttan?
P = Hur många dagar sedan du tvättat byken?
T = Hur många odiskade kärl finns i din diskho, bordssilver borträknat.
K = Hur många rumskamrater har du? (Föräldrar, syskon, släkting ovs. räknas.)
X = Hur korrupta är dina rumskamrater? (1-10, om 10 är ”året runt togafestande och sniffande av Omo.”)
Y = Sannolikheten att dina rumskamrater är på plats? (1-10, om 10 är ”deras jobb kräver aktivt dejourering.”)
Om Lätti < 1, efter att du har öppnat dörren springer hon/han iväg, om hon/han ännu är vid medvetande.
Om 1 ≤ Lätti < 2, kasta snabbt ut din rumskamrat och ring städfirman.
Om Lätti ≥ 3, ingen fara, bjud henne/honom bara djupare in.
Borde jag skaffa husdjur?
Om du har tänkt på att skaffa ett husdjur så rekommenderas att du prövar denna formel före du skaffar ett. För att vara säker på att du gör rätt val. 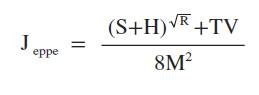
S = Hur stor djurvän är du? (1-10, om 10 är ”älskar alla världens djur.”)
H = Hur bra vårdnadshavare är du? (1-10, om 1 är ”min plastkaktus dog i törst.”)
R = Hur mycket mer kärlek behöver du till i ditt liv (1-10, om 10 är ”senaste ömhetstillfället var handskakningen med tv-reparatören.”)
T = Hur många lediga timmar har du i dagen?
V = Hur ansvarsfull är du? (1-10, om 1 är ”skatten och barnen klara sig själv.”)
M = Hur många dagar i rad har du varit på resa de sex senaste månaderna?
Om Jeppe < 1, ett passligt husdjur för dig är en amöba.
Om 1 ≤ Jeppe ≤ 2, du kan skaffa en självskötande guldfisk.
Om 2 ≤ Jeppe ≤ 3, du kan skaffa dig någon slags katt.
Om Jeppe ≥ 3, du kan skaffa en hund åt dig.
Det perfekta spektrumexemplet
Om vi tar Anna och Pelle (namnen ändrade) för att kolla om de är mera än bara vänner. Anna och Pelle har känt varandra i 13 månader och Anna tycker att Pelle är en femma på attraktivskalan 1-10. Det enda som har hänt mellan de två är en puss på kinden, som inte har särskilt stor betydelse för vår formel. Anna och Pelles framtid ser väldigt olika ut och deras bakgrund med, men Anna är en otroligt bra vän till Pelle och för Anna är vänner väldigt viktiga.
Från detta får vi:
P = 0
Kp = 0
Kg = 0
V = 5
S = 0
T = 13
Y = 2
A = 9
så vi får att Suhde = – 84.5653, som < 0, vilket betyder att Anna och Pelle bara är vänner.
Robert
 , där
, där = x + y") ifall
ifall  , och
, och = x") ifall
ifall  .
.\cdot y \qquad \: (1)") .
. , vilket vi inte ville. Vi borde alltså i fallet
, vilket vi inte ville. Vi borde alltså i fallet  att försvinna. Ett sätt är att istället använda sig av formeln
att försvinna. Ett sätt är att istället använda sig av formeln") .
. . Tyvärr så fungerar den ej i fallet
. Tyvärr så fungerar den ej i fallet  närmare märker vi även att den inte är kontinuerlig i hela
närmare märker vi även att den inte är kontinuerlig i hela  . Problempunkterna är punkterna av typen
. Problempunkterna är punkterna av typen ") där
där  . Om vi t.ex. slår fast x-koordinaten att vara 2, ser vi att det för gränsvärdena gäller att
. Om vi t.ex. slår fast x-koordinaten att vara 2, ser vi att det för gränsvärdena gäller att  = \lim\limits_{y \to 2^{-}} f(2,y) = 4") , men att
, men att  = 2") . Vårt mål var att beskriva funktionen
. Vårt mål var att beskriva funktionen  .
. och antalet signifikanta siffror att vara
och antalet signifikanta siffror att vara  och
och  , ser vi att vi kring talet
, ser vi att vi kring talet  kan representera skillnader av storleksordningen
kan representera skillnader av storleksordningen  , medan vi kring talet
, medan vi kring talet  endast kan representera skillnader av storleksordningen
endast kan representera skillnader av storleksordningen  ! Därmed om vi t.ex. skulle göra beräkningnen
! Därmed om vi t.ex. skulle göra beräkningnen  skulle resultatet vara
skulle resultatet vara ") , som fungerar bra förutom att vi kan tvingas dela med noll. För att undvika division med noll kan vi modifiera formeln på följande sätt:
, som fungerar bra förutom att vi kan tvingas dela med noll. För att undvika division med noll kan vi modifiera formeln på följande sätt: + \varepsilon} \cdot y \qquad \: (2′)") ,
, är ett till absolutbeloppet mycket litet positivt tal (storleken på talet beror på representationen av decimaltalen). Matematiskt sett gäller naturligtvis inte att
är ett till absolutbeloppet mycket litet positivt tal (storleken på talet beror på representationen av decimaltalen). Matematiskt sett gäller naturligtvis inte att  + \varepsilon = x-y") , men p.g.a. bristerna i decimaltalsberäkningen kommer likheten att gälla ifall
, men p.g.a. bristerna i decimaltalsberäkningen kommer likheten att gälla ifall  och
och  är olika och är tillräckligt stora. Kvoten
är olika och är tillräckligt stora. Kvoten  + \varepsilon}") är alltså
är alltså  ifall
ifall ") kravet att
kravet att  = x + y") om
om  och därmed är
och därmed är  , eftersom vi kan representera tal noggrant kring noll. Därmed undviker vi division med noll och kvoten
, eftersom vi kan representera tal noggrant kring noll. Därmed undviker vi division med noll och kvoten  = x") ifall
ifall ![hoffman02450[1]](http://spektrum.fi/spektraklet/wp-content/uploads/2014/07/hoffman024501.jpg)