Knutar och knopar är användbara i alla möjliga sammanhang, till exempel då man förtöjer båtar eller knyter skor. Det finns alla möjliga knopar för olika ändamål och det skulle ju förstås vara intressant att veta hur många knopar det egentligen finns. Inom topologin klassificerar man knopar med hjälp av dess symmetri och antalet gånger repet korsar sig själv. Till skillnad från knutar man använder i vardagen, så är repändarna inom knutteori förenade så att knuten inte går att knyta upp. Den enda icke-knuten är en cirkel där repet inte korsar sig själv en enda gång. Däremot finns det en hel del icke-knutar som är så ”ihoptvinnade” att man inte direkt ser att det inte är en egentlig knut.
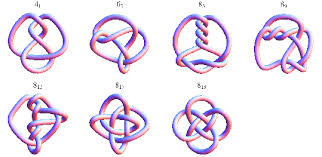
Olika knutar och knutkonfigurationer
Antalet olika knutar man för tillfället känner till:
Antalet ”korsningar” Antalet knutar
3 1
4 1
5 2
6 3
7 7
8 21
9 49
10 165
11 552
12 2176
13 9988
14 46 972
15 253 293
16 1 388 705
Två knutar är identiska om man kan manipulera den ena så att den blir likadan som den andra utan att klippa av repet. Däremot är det inte helt lätt att komma fram till vilka knutar som är identiska och vilka som är olika. År 1899 publicerade C. N. Little en lista på 43 olika knutar som alla hade tio ”korsningar”. Det visade sig först 75 år senare att det bland dessa 43 knutar fanns två stycken identiska knutar, nämligen knutarna 10_161 och 10_162. Det var juristen Kenneth Perko som genom att manipulera knutar gjorda av rep på sitt golv kom fram till att två av Littles knutar var identiska. De här två identiska knutarna kallas därför för Perkopar. Här nedan är knut 10_161 och 10_162, så du kan själv prova att lösa problemet.
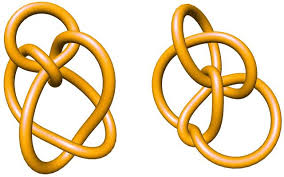
Perkopar
I och med denna upptäckt märker man att det inte krävs att man är matematiker på heltid för att göra intressanta upptäckter inom matematik. Frågeställningen i sig är väldigt enkel; ”Är de här två knutarna identiska?”, men svaret kan vara mycket svårt att få fram. På grund av det här krävs det ändå inte så mycket matematisk kunskap för det här, utan man kan, så som Perko, bevisa svaret med hjälp av riktiga rep och knutar. Man måste bara vara tillräckligt intresserad och investerar lite tid i det hela.
Knutar är väldigt bekanta och vardagliga fenomen, som används i många former av handarbete, till exempel stickning, virkning och makramé. Forskningen inom knutteori handlar till stor del om knutgrupper och att klassificera knutar. Knutteorin har även kopplingar till matematiska metoder inom statistisk mekanik och kvantfältsteori. Dessutom kan knutteori användas för att förstå molekylers kiralitet och hur enzymer bearbetar DNA.
Som en äkta fysiker och experimentalist kännde jag mig förstås tvungen att knyta några egna knutar. Jag vågade mig ändå inte på att börja manipulera Perkos knutar, utan jag gjorde istället två stycken knutar med åtminstone 100 korsningar. De kan användas till exempelvis som nyckelringar.


 , där
, där = x + y") ifall
ifall  , och
, och = x") ifall
ifall  .
.\cdot y \qquad \: (1)") .
. , vilket vi inte ville. Vi borde alltså i fallet
, vilket vi inte ville. Vi borde alltså i fallet  att försvinna. Ett sätt är att istället använda sig av formeln
att försvinna. Ett sätt är att istället använda sig av formeln") .
. . Tyvärr så fungerar den ej i fallet
. Tyvärr så fungerar den ej i fallet  närmare märker vi även att den inte är kontinuerlig i hela
närmare märker vi även att den inte är kontinuerlig i hela  . Problempunkterna är punkterna av typen
. Problempunkterna är punkterna av typen ") där
där  . Om vi t.ex. slår fast x-koordinaten att vara 2, ser vi att det för gränsvärdena gäller att
. Om vi t.ex. slår fast x-koordinaten att vara 2, ser vi att det för gränsvärdena gäller att  = \lim\limits_{y \to 2^{-}} f(2,y) = 4") , men att
, men att  = 2") . Vårt mål var att beskriva funktionen
. Vårt mål var att beskriva funktionen  .
. och antalet signifikanta siffror att vara
och antalet signifikanta siffror att vara  och
och  , ser vi att vi kring talet
, ser vi att vi kring talet  kan representera skillnader av storleksordningen
kan representera skillnader av storleksordningen  , medan vi kring talet
, medan vi kring talet  endast kan representera skillnader av storleksordningen
endast kan representera skillnader av storleksordningen  ! Därmed om vi t.ex. skulle göra beräkningnen
! Därmed om vi t.ex. skulle göra beräkningnen  skulle resultatet vara
skulle resultatet vara ") , som fungerar bra förutom att vi kan tvingas dela med noll. För att undvika division med noll kan vi modifiera formeln på följande sätt:
, som fungerar bra förutom att vi kan tvingas dela med noll. För att undvika division med noll kan vi modifiera formeln på följande sätt: + \varepsilon} \cdot y \qquad \: (2′)") ,
, är ett till absolutbeloppet mycket litet positivt tal (storleken på talet beror på representationen av decimaltalen). Matematiskt sett gäller naturligtvis inte att
är ett till absolutbeloppet mycket litet positivt tal (storleken på talet beror på representationen av decimaltalen). Matematiskt sett gäller naturligtvis inte att  + \varepsilon = x-y") , men p.g.a. bristerna i decimaltalsberäkningen kommer likheten att gälla ifall
, men p.g.a. bristerna i decimaltalsberäkningen kommer likheten att gälla ifall  och
och  är olika och är tillräckligt stora. Kvoten
är olika och är tillräckligt stora. Kvoten  + \varepsilon}") är alltså
är alltså  ifall
ifall ") kravet att
kravet att  = x + y") om
om  och därmed är
och därmed är  , eftersom vi kan representera tal noggrant kring noll. Därmed undviker vi division med noll och kvoten
, eftersom vi kan representera tal noggrant kring noll. Därmed undviker vi division med noll och kvoten  = x") ifall
ifall  möjliga koder, så ifall du prövar dem alla, måste dörren öppnas förr eller senare. För inmatandet av alla koder måste du då slå in
möjliga koder, så ifall du prövar dem alla, måste dörren öppnas förr eller senare. För inmatandet av alla koder måste du då slå in  siffror.
siffror.
 olika koder, nämligen koderna
olika koder, nämligen koderna  ,
,  ,
,  . I vilken ordning skulle man slå in siffror i detta fall för att med så liten möda som möjligt få upp dörren? En möjlighet är att slå in sekvensen
. I vilken ordning skulle man slå in siffror i detta fall för att med så liten möda som möjligt få upp dörren? En möjlighet är att slå in sekvensen  . Den innehåller alla koder:
. Den innehåller alla koder: är en sekvens av siffror 0 och 1. Ifall den innehåller alla fyra olika koder av längd två, måste var och en av koderna starta vid olikt index i sekvensen. Därmed kan den sista koden starta som tidigast vid index 4, och eftersom den är av längden två, måste sekvensen
är en sekvens av siffror 0 och 1. Ifall den innehåller alla fyra olika koder av längd två, måste var och en av koderna starta vid olikt index i sekvensen. Därmed kan den sista koden starta som tidigast vid index 4, och eftersom den är av längden två, måste sekvensen  .
.
 = 10003") (börjandes med siffrorna
(börjandes med siffrorna  ) som innehåller alla koder, en klar förbättring till att vara tvungen att mata in 40000 siffror!
) som innehåller alla koder, en klar förbättring till att vara tvungen att mata in 40000 siffror! och sifferantal (dvs. baser)
och sifferantal (dvs. baser)  alltid skapa en sekvens som inte upprepar någon kod två gånger? Svaret är kanske aningen överraskande ja. Beviset i sin helhet, till vilket det finns en länk i slutet av artikeln, är lite för invecklat för att tas upp i denna artikel, men det bygger på följande observation: Antag för enkelhetens skull att vi vill skapa koder av längd 4 som består av siffrorna 0, 1, 2 och 3. Ifall vi har någon kod, t.ex.
alltid skapa en sekvens som inte upprepar någon kod två gånger? Svaret är kanske aningen överraskande ja. Beviset i sin helhet, till vilket det finns en länk i slutet av artikeln, är lite för invecklat för att tas upp i denna artikel, men det bygger på följande observation: Antag för enkelhetens skull att vi vill skapa koder av längd 4 som består av siffrorna 0, 1, 2 och 3. Ifall vi har någon kod, t.ex.  , kan efter denna kod i sekvensen följa endast en kod som börjar med siffrorna
, kan efter denna kod i sekvensen följa endast en kod som börjar med siffrorna  och slutar med en av siffrorna 0, 1, 2 eller 3. Detta gör att sekvensen blir mycket symmetrisk, eftersom det efter någon av koderna
och slutar med en av siffrorna 0, 1, 2 eller 3. Detta gör att sekvensen blir mycket symmetrisk, eftersom det efter någon av koderna  endast kan följa någon av koderna
endast kan följa någon av koderna  .
.